以前からPacBioでHLA遺伝子をシークエンスしている先生の発表があったのと、この業界についてはほとんど素人だったので、勉強もかねて。学会についてはこちら
この学会では、輸血・臓器・造血といった、移植全般の「組織適合性」に関して、大学研究者から医療関係者、日本赤十字、現場のティシュータイパー、といった方々が集まって最新の技術を発表したり、現場の問題点を提起したり、活発に議論が交わされていました。
企業からもタイピング受託会社や、タイピング装置やキットの輸入商社、メーカーなどが参加。
学会の規模は、そうですね、実感としては「ゲノム微生物学会」くらいの大きさかな。
さて、HLAについて、もし基礎的なバックグラウンドを知りたいかたは、先ほどの学会ホームページのここがとても詳しいです。
私もこのページで勉強しました。
ざっくり言うと、移植のときなどにドナーとレシピアントとの間で、適合するかどうか、は、HLAという遺伝子のSNPの型で決めるんです。
ひとつの遺伝子にSNPがいくつもあって、その組み合わせで、何千通りというハプロタイプができる。
HLAはA、B、C、DRB、DQB、DPBなどなどいくつかあり、タイピングに用いられる遺伝子はだいたい決まっています。
その遺伝子のSNP型を、ビーズ、PCR、またはシークエンスで判定するということ。
今、HLAタイピングの主流はビーズです。
その理由は、①簡単、②低コスト、③世界中でバリデートされている
から。
ビーズで検出すると、同じ遺伝子上でも離れた場所にある2つのSNPのハプロタイプはわからない。
これをAmbiguity問題、といいます。
シークエンス法に比べると、精度は落ちる。
 |
| GenDX社のウェブサイトから |
プライマーはもちろん保存された領域に設定される。
このプライマーでちゃんと増えたら、次に断片化する。
断片化した後、シークエンスする場所を濃縮するか、あるいはそのままシークエンスする。
あれ? 何で断片化するの?
と思ったかた、あなたの頭はPacBio向きです。
PCRで増幅したHLA遺伝子は、だいたい4kbから10kbかそれより少し長いくらい。
PacBioならそのまま読めますよね。
そうです。読めます。
断片化するのは、ショートリードのときだけ。
NGSとHLAタイピングをもっと詳しく知りたい!という方はこのレビューがおすすめ

Hosomichi et al., (2015) The impact of next-generation sequencing technologies on HLA research. J of Human Genetics.
HLAタイピングの方法、ソフトウェアの種類、長所短所などがまとめられています。
有償ソフトウェアなどは各社独自のマッピング方法を開発して、精度を上げています。
そして、アレルごとにコンセンサスを出して、アレルの型を決める
ここはPacBioでのHLAシークエンスに一番ノウハウがあると思いますが、いかんせん、企業なので情報はあまり出てこない。
では、イギリスのAnthony Nolanはどうかな?ここは公共機関。論文もあります。
 Mayor et al., (2015) HLA Typing for the Next Generation. PLOS One.
Mayor et al., (2015) HLA Typing for the Next Generation. PLOS One.

 |
| Hosomichi et al. (2015) |
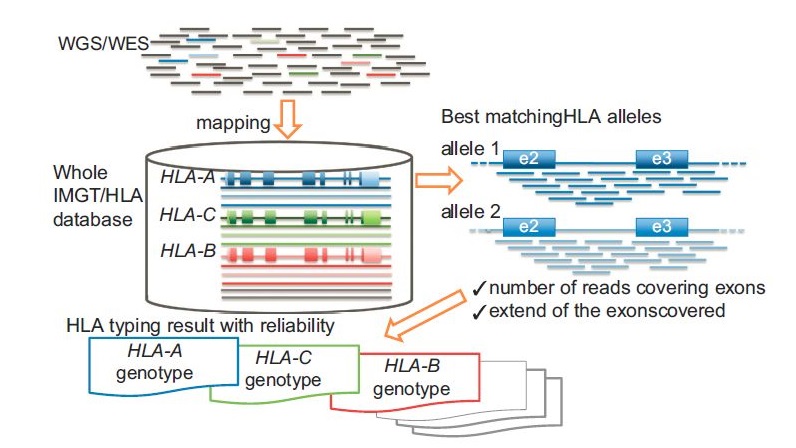
PacBioの場合も、長いリードで遺伝子全体を読みますが、そのあとデノボでクラスタリングをつくり、アレルごとにコンセンサス配列を作ります。
先にデータベースにマッピングするのではなく、アレルごとの遺伝子全体のコンセンサス配列をつくってから、データベースを参照して型を判定するのです。
(正確には、遺伝子全体を読むのはClass Iと呼ばれる比較的短い、とはいっても5kbくらい、の遺伝子。Class IIと呼ばれる遺伝子群は、10kb以上あるが、それくらい長いとPCRすること自体が難しい。そこで遺伝子の一部を増幅することが多い)
このように、NGS、特にPacBioで読めば、Ambiguity無しに、正確なHLA型を判定することが可能です。
でも、タイピングにかかるコストは若干高め。
ライブラリ作製にかかる手間は、ビーズ法に比べれば、かかる。これは認めます。
では、どういう場合に、PacBioがHLAタイピングに使用されているのか?
アメリカには、Histogenetics社という、HLAタイピングの専門会社があります。
この会社はMiSeqを47台、PacBioを1台保有し(もちろんキャピラリーはたっくさん保有)、Sequence Based Typing (SBT)をガンガンやっています。
顧客は主にNMDP(National Marrow Donor Program)のようなバンク。
MiSeqを使ったタイピングでもキャピラリーを使ったタイピングでも、データベースに合わなかったり新規の可能性があるような場合、PacBioの登場。
昨年はまだ慣れていなかったテクニシャンも、もうPacBioかんたーん!って言っているそうです(Histogenetics社のCEO曰く)。
タイピングの方法も、自分たちで作ったデータベースに独自のプログラムを使って、行なっているとのこと。ここはPacBioでのHLAシークエンスに一番ノウハウがあると思いますが、いかんせん、企業なので情報はあまり出てこない。
では、イギリスのAnthony Nolanはどうかな?ここは公共機関。論文もあります。

新しいアレルも発見されています

Hayward et al., (2015) The novel HLA-B*44 allele, HLA-B*44:220, identified by Single Molecule Real-Time DNA sequencing in a British Caucasoid male. Tissue Antigens.
人類遺伝学会などでも関連する発表がありそうな予感。
PacBioの可能性が試されるときです!
0 件のコメント:
コメントを投稿